How much am I worth?
How much am I worth?

How much am I worth?
The hardest part of job hunting is when the recruiter turns to you and says “So, what kind of salary are you looking for?”
At this moment my heart dropped and I started to flip through the story of my life. “I won that award that time, plus $800”, “I fell off that slide when I was 3 years old, subtract $2k”, “I am 22 without a job, subtract $5k”, “I have not read more than 12 books in my life, subtract $10k”… I realized that when put on the spot, I only think of the negative parts of my life instead of all the great things that I have done.
I realized that this would be a great project to create. A model that can take in either a resume or a job posting as an input and the output would be a salary or salary range.
I decided to use Google Jobs as my source of jobs. This is because they aggregate their jobs from a bunch of other job platforms. Additionally, they post salary estimates from ‘Glassdoor”, “Built in NYC”, and “PayScale”.
I downloaded a chrome driver to be used with Selenium.
I downloaded a chrome driver to be used with Selenium.
You can use this blog post by Atindra Bandi to learn more about Selenium and how it can be used.
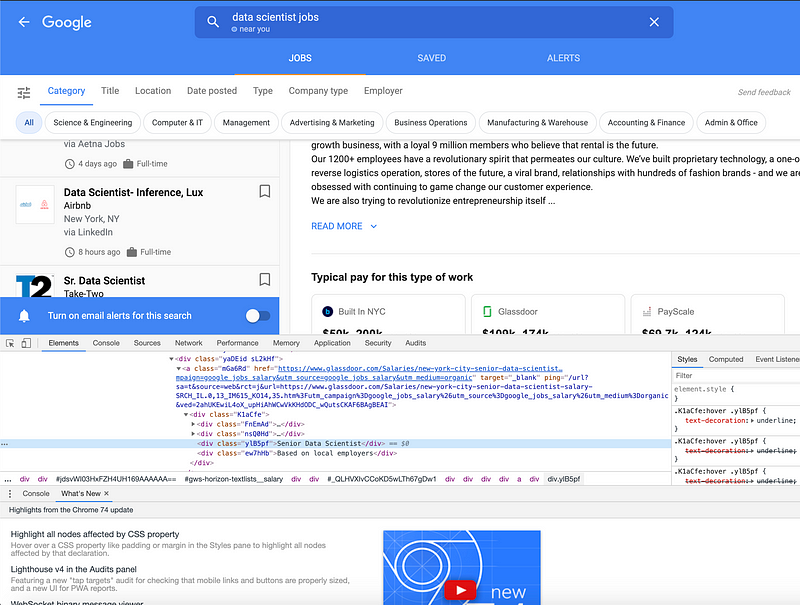
After inspecting the Google job platform, I was able to identify which data I would pull from the job posting. I wanted the title, company name, job posting, location, and the estimated salary (From Glassdoor or the others).
I started by creating a function to take an input of a search term and Selenium would open up chrome and open a Google job search using the search term given.
def open_link(job_name):
job_name = job_name.replace(' ','_')
job_url_name = job_name.replace('_','+')
url = f'https://www.google.com/search?q={job_url_name}&ibp=htl;jobs#fpstate=tldetail&htidocid='
driver = webdriver.Chrome(executable_path='./chromedriver')
driver.get(url)
open_link(str(input())
Once I used Selenium to open up the browser and perform the search, I inspected and was able to identify how I would be instructing BeautifulSoup to pull the data that we want.
def get_job_data():
# Get HTML from the page
soup = BeautifulSoup(driver.page_source, 'lxml')
jobs = soup.find_all('li')
job_list = []
# Loop through each job and save the data to a list of dictionaries
for job in jobs:
job_dic = {}
job_dic['title']= job.find('h2',{'jsname':'SBkjJd'}).text
job_dic['company']=job.find('div',{'class':'pbHUre tcoBdd'}).text
job_dic['body']=job.find('span',{'style':'line-height:1.5em'}).text
job_dic['location']=job.find_all('div',{'class':'tcoBdd'})[1].text
try:
job_dic['salary']=job.find('span',{'class':'zE8vH'}).text.replace('CA','')
except:
job_dic['salary']=np.nan
# Append the job dictionary to a list
job_list.append(job_dic)
# Create a Data Frame from the list
df = pd.DataFrame(job_list)
return df
job_dataframe = get_job_data()
Now that we have the proper job data, we can continue to pull more jobs from different search words.
I created a function that can pull up to 150 jobs at a time but it will require a little bit of manual scrolling and input.
After running the function, you will be asked to enter a search word (no quotes required). Once the page is opened, scroll on the list of jobs until the page stops refreshing. Once you are done, go back to the script, and type a ‘y’ to proceed. The script will go through each job and pull the necessary data and it will return a DataFrame.
After running the function, you will be asked to enter a search word (no quotes required). Once the page is opened, scroll on the list of jobs until the page stops refreshing. Once you are done, go back to the script, and type a ‘y’ to proceed. The script will go through each job and pull the necessary data and it will return a DataFrame.
def manually_get_job_data():
job_name = str(input("Enter Job Title")).replace(' ','_')
job_url_name = job_name.replace('_','+')
pre_url = f'https://www.google.com/search?q={job_url_name}&ibp=htl;jobs#fpstate=tldetail&htidocid='
driver = webdriver.Chrome(executable_path='./chromedriver')
driver.get(pre_url)
proceed = 0
while proceed != 'Y':
proceed = str(input('Are You Ready To Proceed? (Y/N)')).upper()
for i in [pre_url+link.attrs['id'][4:] for link in BeautifulSoup(driver.page_source, 'lxml').find_all('div',{'jsname':'x5pWN'})]:
driver.get(i)
soup = BeautifulSoup(driver.page_source, 'lxml')
jobs = soup.find_all('li')
job_list = []
for job in jobs:
if (job.find('h2',{'jsname':'SBkjJd'}) != None) and (len(job.find_all('div',{'class':'tcoBdd'}))>1):
job_dic = {}
job_dic['title']= job.find('h2',{'jsname':'SBkjJd'}).text
job_dic['company']=job.find('div',{'class':'pbHUre tcoBdd'}).text
job_dic['body']=job.find('span',{'style':'line-height:1.5em'}).text
job_dic['location']=job.find_all('div',{'class':'tcoBdd'})[1].text
try:
job_dic['salary']=job.find('span',{'class':'zE8vH'}).text.replace('CA','')
except:
job_dic['salary']=np.nan
job_dic['avg_salary']=avg(job_dic['salary'])
job_list.append(job_dic)
new = pd.DataFrame(job_list)
return new df = manually_get_job_data()
After pulling over 6,000 jobs, it was time to go through the data and clean it up.
Our data had 2 issues:
1. Only about 3,000 columns had estimated salary data
2. The estimated salary data was a range of values (EX: $75k — $120k)
1. Only about 3,000 columns had estimated salary data
2. The estimated salary data was a range of values (EX: $75k — $120k)
In order to fix this, I dropped all rows that did not have a salary, and I created a function to go through each cell in the salary column and find the average salary for the range (EX: $75k — $120k = $97,500). Once it got all of the averages, I created a new column in the DataFrame to store all of these new numbers.
In order to run text through a statistic model, we would have to turn our text into numbers.
The cleansing I used for the text consisted of tokenizing, lemmatizing, removing stop words, and vectorizing.
I decided to use SkLearn’s TFIDF-Vectorizer to turn the text into numbers based on the frequency of the word in the document, and the frequency of the word in our entire corpus (all of our documents).
The cleansing I used for the text consisted of tokenizing, lemmatizing, removing stop words, and vectorizing.
I decided to use SkLearn’s TFIDF-Vectorizer to turn the text into numbers based on the frequency of the word in the document, and the frequency of the word in our entire corpus (all of our documents).
They hyper-parameters that I decided to use for the vectorizer was
n_grams = (1,3), max_df = .85 min_df = .15 binary = True
Now that the data was ready to be put through a stats model, I performed a train_test_split on it and initially ran it through a LinearRegression. This was to get a “base score” that I can use to see the accuracy of my other models, and also, for inference.
I went on to use Ridge, Lasso, Random Forest, Gradient Boost, and even a Neural Network.
I went on to use Ridge, Lasso, Random Forest, Gradient Boost, and even a Neural Network.
For all of these models, my metric was Root Mean Square Error.
Glassdoor’s normal range ± $32,214
LinearRegression — $30,595
Lasso — $30,458
Ridge — $30,560
Random Forest — $19,290
Gradient Boost — $18,379
Neural Network — $28,736
Glassdoor’s normal range ± $32,214
LinearRegression — $30,595
Lasso — $30,458
Ridge — $30,560
Random Forest — $19,290
Gradient Boost — $18,379
Neural Network — $28,736
The model predicts salaries with a lower error that Glassdoor!
I then decided to place my resume inside of the model to see what it predicted.

This is a pretty accurate estimation for entry level jobs as a Data Scientist / Data Analyst in New York City.
Thank you for reading!
P.S. I am continuously working on this project to make it more accurate. I recently performed a lot of feature engineering and vectorized the location and the job title. The current error that I am receiving is around $14,500!
I will post soon with my updates and a link to my github to learn more about my project.
I will post soon with my updates and a link to my github to learn more about my project.
Comments